

String manipulation is a common task in Python programming. In this blog post, we will explore ten popular string operation comparisons in Python, discussing why one approach is more efficient than the other. We will also provide code snippets for each comparison, as well as links to more detailed information and benchmark results. By the end of this post, you will have a better understanding of how to choose the right string operation for your specific use case.
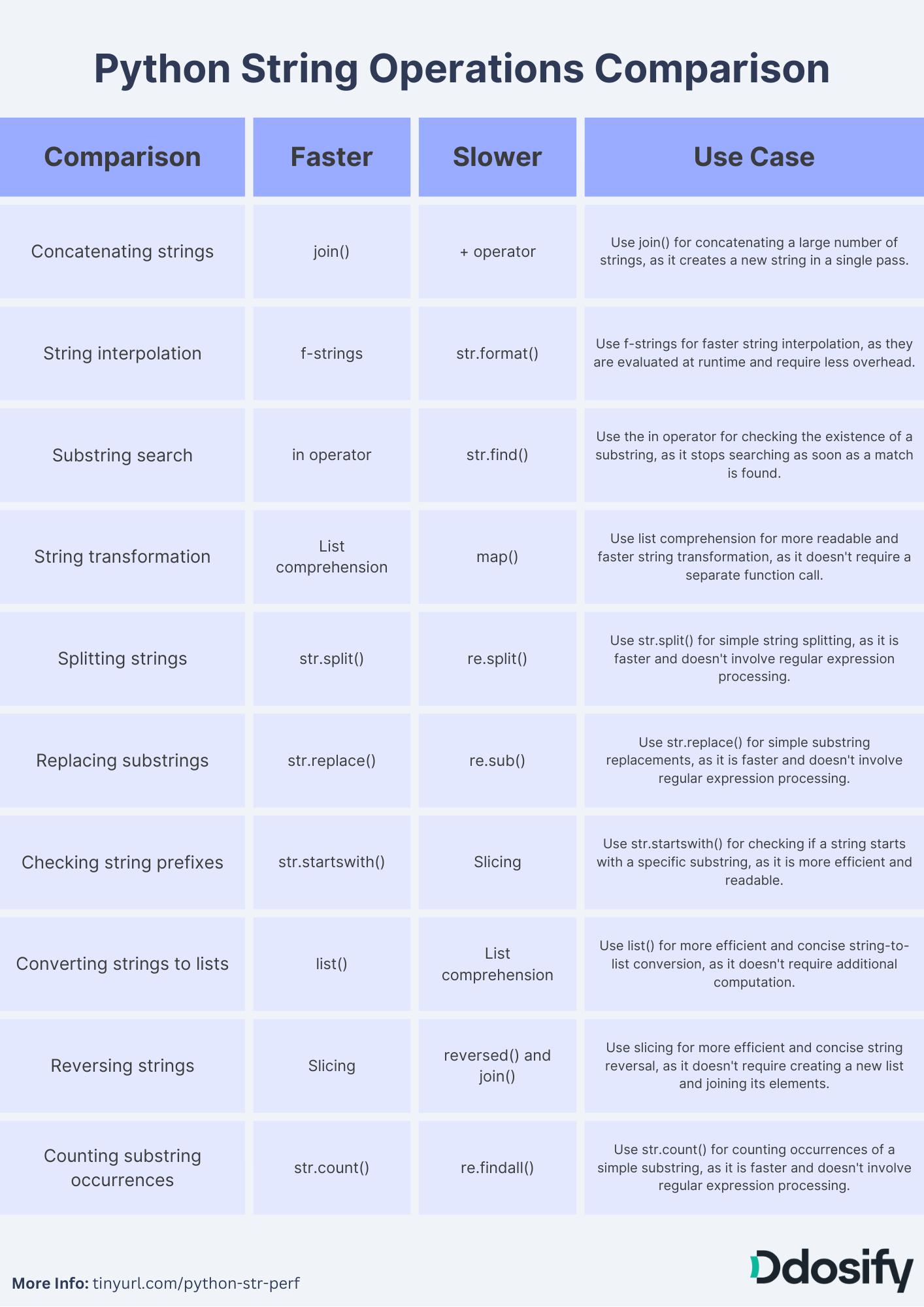
1. Concatenating strings using join() vs. + operator
The join() method is generally more efficient when concatenating a large number of strings, as it creates a new string in a single pass. On the other hand, the + operator creates a new string for each concatenation, which can lead to slower performance
# Using join()
result = ''.join(['a', 'b', 'c'])
# Using +
result = 'a' + 'b' + 'c'
2. String interpolation using f-strings vs. str.format()
F-strings, introduced in Python 3.6, are faster than the str.format() method, as they are evaluated at runtime and require less overhead. The str.format() method, while still useful, may be slower due to its more complex parsing.
# Using f-strings
name = "John"
age = 30
result = f"My name is {name} and I am {age} years old."
# Using str.format()
result = "My name is {} and I am {} years old.".format(name, age)
3. Using in operator vs. str.find() for substring search
The in operator is more efficient for checking the existence of a substring within a string, as it stops searching as soon as a match is found. The str.find() method, while still functional, returns the index of the first occurrence or -1 if not found, which may be slower in some cases.
# Using in
substring_present = "abc" in "abcdef"
# Using str.find()
substring_present = "abcdef".find("abc") != -1
4. Using list comprehension vs. map() for string transformation
List comprehension is generally more readable and faster than using map() for transforming strings. This is because map() requires a separate function call, which can add overhead.
# Using list comprehension
result = [x.upper() for x in ["apple", "banana", "cherry"]]
# Using map()
result = list(map(lambda x: x.upper(), ["apple", "banana", "cherry"]))
5. Splitting strings using str.split() vs. re.split()
For simple string splitting, str.split() is faster and more efficient than re.split(), as it does not involve the overhead of regular expression processing. However, re.split() can be more powerful when dealing with complex splitting patterns.
# Using str.split()
result = "apple,banana,cherry".split(",")
# Using re.split()
import re
result = re.split(",", "apple,banana,cherry")
6. Replacing substrings using str.replace() vs. re.sub()
For simple substring replacements, str.replace() is faster and more efficient than re.sub(), as it does not involve the overhead of regular expression processing. However, re.sub() is more powerful when dealing with complex replacement patterns.
# Using str.replace()
result = "I love apples".replace("apples", "bananas")
# Using re.sub()
import re
result = re.sub("apples", "bananas", "I love apples")
7. Checking string prefixes using str.startswith() vs. slicing
Using the str.startswith() method is more efficient and readable than slicing for checking if a string starts with a specific substring. Slicing requires more computation and can be less clear.
# Using str.startswith()
result = "apple".startswith("app")
# Using slicing
result = "apple"[:3] == "app"
8. Converting strings to lists using list() vs. list comprehension
The list() constructor is generally more efficient and concise for converting strings to lists. List comprehension, while still functional, may be slower and less readable for this specific use case.
# Using list()
result = list("apple")
# Using list comprehension
result = [c for c in "apple"]
9. Reversing strings using slicing vs. reversed() and join()
Slicing is a more efficient and concise way to reverse a string in Python, as it does not require the overhead of creating a new list and joining its elements. Using reversed() and join() is less efficient due to the additional steps involved.
# Using slicing
result = "apple"[::-1]
# Using reversed() and join()
result = ''.join(reversed("apple"))
10. Counting occurrences of a substring using str.count() vs. re.findall()
For counting occurrences of a simple substring, str.count() is faster and more efficient than re.findall(), as it does not involve the overhead of regular expression processing. re.findall() can be more powerful when dealing with complex matching patterns but may be slower for simple use cases.
# Using str.count()
result = "I love apples and apples are tasty".count("apples")
# Using re.findall()
import re
result = len(re.findall("apples", "I love apples and apples are tasty"))
Conclusion
Optimizing string operations in Python can make a significant difference in the performance of your applications. By following these tips and utilizing the provided code snippets, you can enhance the efficiency of your string manipulation tasks.
After implementing these performance improvements, it's essential to test your application under real-world conditions. Our load testing SaaS platform provides a comprehensive solution to assess your application's performance, scalability, and reliability. Sign up today and make sure your Python code is ready to handle the demands of the modern web!
For more information on Python performance optimization and other related topics, we recommend checking out the following resources:
- Python official documentation
- Python performance tips by the Python Software Foundation
- "Fluent Python" by Luciano Ramalho
Lastly, If you'd like to have a quick reference guide at your fingertips, we've created a cheat sheet.
Share on social media: